Meta Mask
Conntect to you Metamask wallet
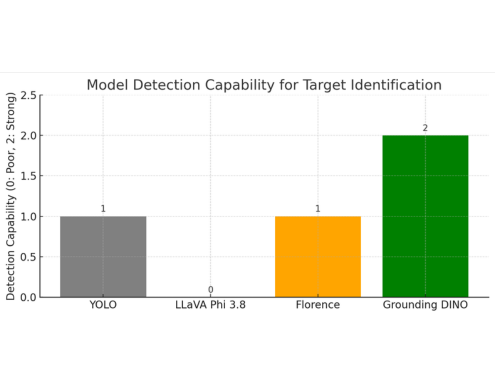
YOLO is efficient and quick for real-time object detection, but it is restricted to a pre-configured set of predefined classes. It has no native support for text-based grounding or open-vocabulary detection. Due to the lack of labeled training data and the high training time and computational power required, this was rejected. Grounding DINO supports zero-shot detections with no training, making it a better fit for our needs.
LLaVA Phi 3.8 is a combination of vision-language models designed for tasks like visual question answering and multi-modal understanding. While it showed strong performance in reasoning and image-text dialogue, it was not intended for localization or generating accurate bounding boxes. It lacked support for tasks such as multi-object grounding. Even though it provided good descriptions, its capabilities were limited—it often produced hallucinations when asked to localize objects. The main reason it was not considered was that it didn’t produce structured output. Grounding DINO addressed this limitation by providing structured output with accurate bounding boxes and minimal hallucination.
Florence is a multi-modal vision-language model capable of handling a wide range of multi-modal tasks. It involved a trade-off—while it offered faster inference in some cases, it was less customizable due to limited support for threshold tuning, unlike Grounding DINO which supports multiple configurable thresholds. It was not optimized for real-time use, and its phrase-based grounding was less effective compared to Grounding DINO. Additionally, it often assigned multiple classes to the same region, leading to ambiguity in the output.
Grounding DINO has been the most practical fit for our use case. It’s built specifically to detect and localize objects based on natural language phrases — which is exactly what we need for ODLC-style tasks. Unlike generic vision-language models, it handles open-vocabulary prompts, multiple object instances, and gives back clean, tightly aligned bounding boxes — all without needing retraining. What also helps is that it supports multiple thresholds — so we can easily tweak confidence levels, IoU (Intersection over Union), and containment to really clean up and refine the results.

To create a high-quality map from a large set of images, the dataset was first split into smaller batches of five images to keep the resolution high and ensure enough overlap. In each batch, keypoints were detected using the SURF (Speeded-Up Robust Features) method, matched using FLANN (Fast Library for Approximate Nearest Neighbours), and aligned using RANSAC (Random Sample Consensus). After alignment, steps like wave correction, multi-band blending, and perspective warping were applied to produce clean mini panoramas. These mini maps were then combined to build one large map, which was finally cropped to a 16:9 aspect ratio.
However, on large datasets, wrong keypoint matching, uneven shapes, visible seams, and unreliable matching with poor overlap made this method ineffective and it was discarded.
In the lat-long approach, metadata from each image was extracted into a CSV file, and every pixel was converted into geographic coordinates, with the center of each image marked. A blank 16:9 canvas was generated using the actual GPS coordinates of the area, based on mission parameters. Each image was then mapped to its corresponding pixel location on the canvas using the metadata. After placement, images were fine-tuned and stitched to ensure seamless blending.
However, this approach failed due to imprecise overlap between images, resulting in tiles being placed side by side instead of forming a unified map. Additionally, neglecting the Earth's curvature introduced spatial distortions—particularly at the edges—causing incorrect scaling and positioning. As a result, the final map lacked geometric consistency and visual continuity.
Parachute payload dropping systems are time-tested mechanisms, widely used in both military and civilian applications for their robust deceleration capabilities. Able to handle payloads ranging from grams to tonnes, parachutes are commonly used in UAVs—particularly fixed-wing platforms that lack hovering capability for precise tethered drops. While highly reliable, parachute systems are less accurate, as wind conditions and trajectory dynamics introduce complexity and reduce precision.

Tethered Systems: Winch-based payload systems offer greater control and are typically used to deploy payloads at a controlled descent rate. In our UAV, we developed and tested three different tethered drop mechanisms:
1. Motor Payload System: This system employs a DC motor to resist the spool's rotation through back EMF, allowing passive control without external power. As the payload descends, it generates back EMF, slowing the fall. While efficient, this system discards the wire after each drop due to automatic detachment requirements in SUAS missions.
2. Retractable Payload System (RPDM): To address the issue of wire disposal, the RPDM integrates smart electronics for automated detachment and motor-powered wire retrieval. Although convenient, this system adds significant weight and introduces more failure points—making it unsuitable for weight-optimized missions like SUAS 2025.
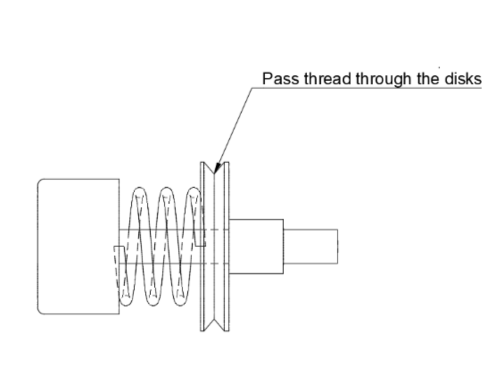
3. Wire Tension Payload System: The third approach utilizes frictional force between tightly spaced clamping discs to regulate descent. While this reduced system weight by 300g, it introduced problems like frequent jamming, thread wear, and dust accumulation, resulting in inconsistent drop times.
Together, these drop mechanisms represent iterative innovation toward achieving optimal trade-offs between weight, reliability, and precision for mission-specific UAV operations.
Select what network and wallet you want to connect below